協同程式與管道 - 教學
在本教學中,您將學習如何在 IntelliJ IDEA 中使用協同程式執行網路請求,而不會阻塞底層執行緒或使用回呼(callback)。
不需要具備協同程式的先備知識,但預期您已熟悉基本的 Kotlin 語法。
您將學習到:
- 為什麼以及如何使用暫停函式(suspending function)來執行網路請求。
- 如何使用協同程式並行地發送請求。
- 如何使用管道(channel)在不同的協同程式之間共享資訊。
對於網路請求,您將需要 Retrofit 程式庫,但本教學中展示的方法同樣適用於任何其他支援協同程式的程式庫。
您可以在專案存儲庫的
solutions分支中找到所有任務的解答。
在您開始之前
下載並安裝最新版本的 IntelliJ IDEA。
在歡迎畫面選擇 Get from VCS 或選取 File | New | Project from Version Control 來複製 專案樣板。
您也可以透過命令列複製它:
Bashgit clone https://github.com/kotlin-hands-on/intro-coroutines
產生 GitHub 開發者權杖
您將在專案中使用 GitHub API。若要獲得存取權限,請提供您的 GitHub 帳戶名稱以及密碼或權杖(token)。如果您啟用了雙重身份驗證,使用權杖就足夠了。
為您的帳戶產生一個新的 GitHub 權杖以使用 GitHub API:
指定權杖的名稱,例如
coroutines-tutorial: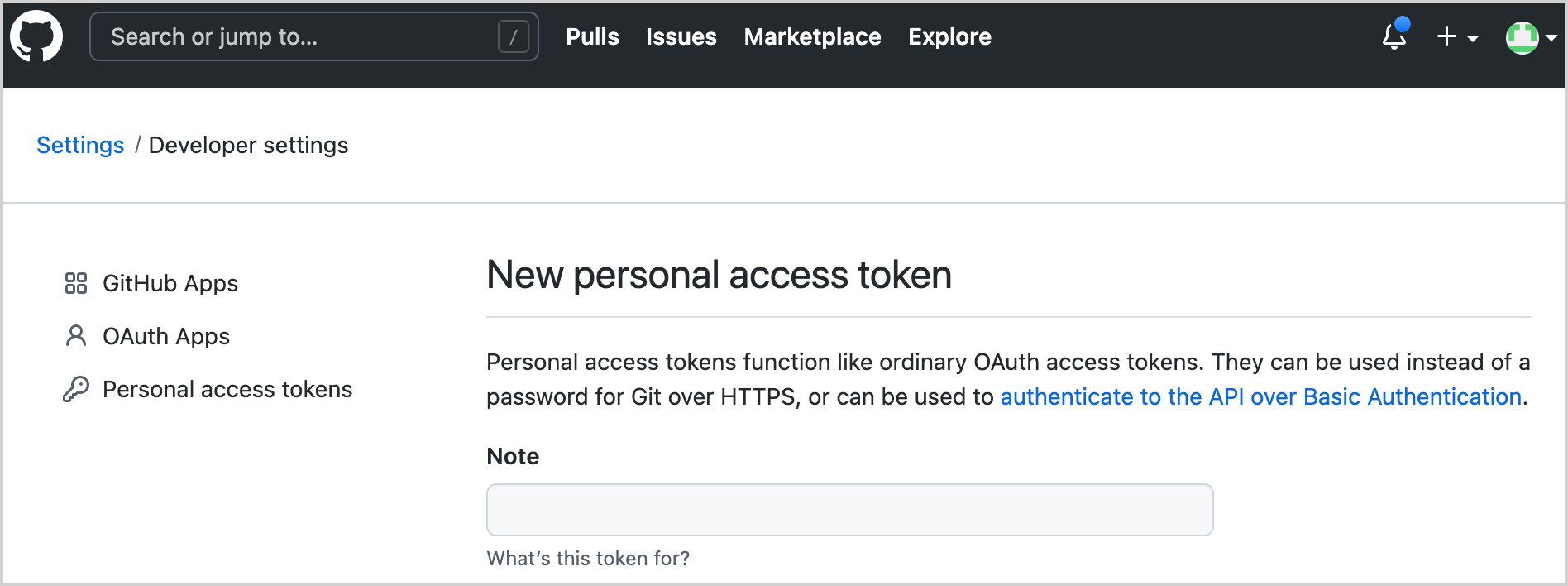
不要勾選任何作用域(scope)。點擊頁面底部的 Generate token。
複製產生的權杖。
執行程式碼
該程式會載入給定組織(預設名稱為「kotlin」)下所有存儲庫的貢獻者。稍後您將加入邏輯,根據使用者的貢獻次數進行排序。
開啟
src/contributors/main.kt檔案並執行main()函式。您將看到以下視窗: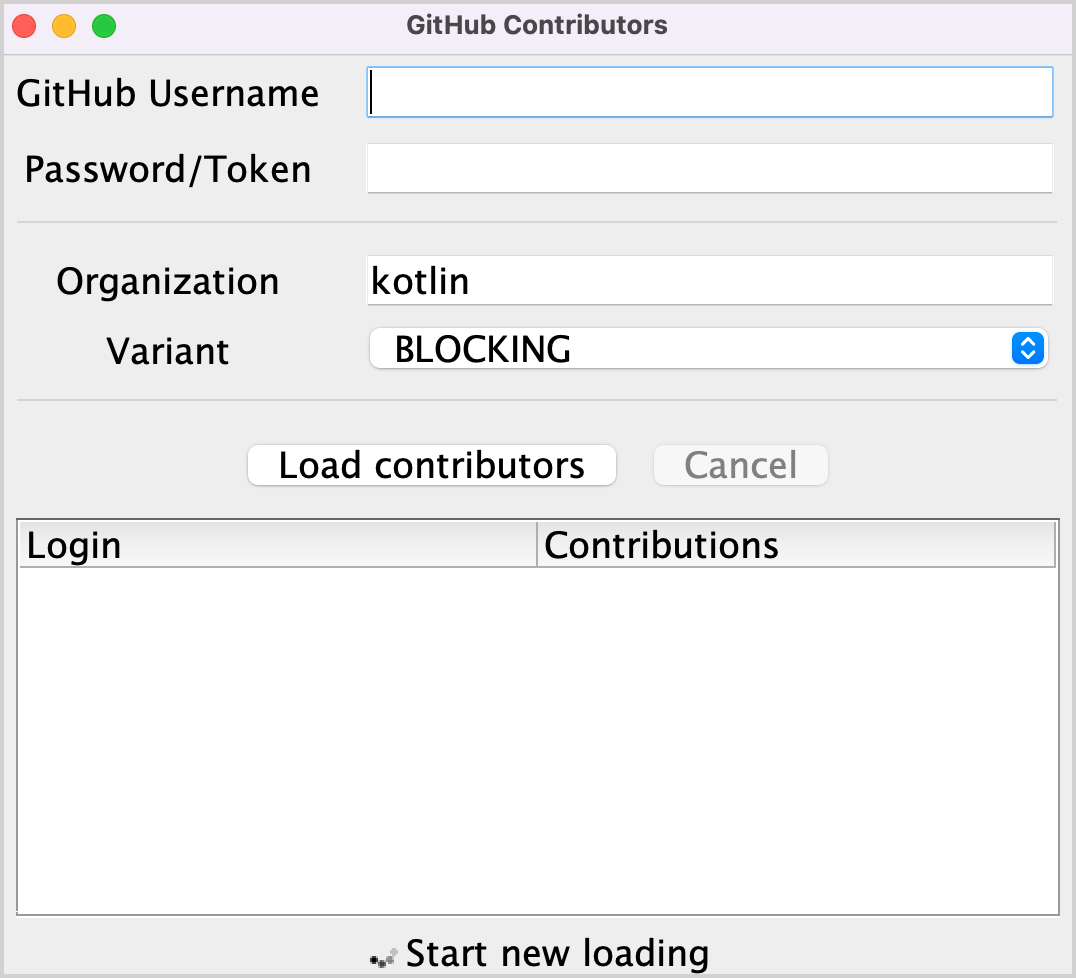
如果字體太小,可以透過修改
main()函式中setDefaultFontSize(18f)的值來調整。在對應的欄位中提供您的 GitHub 使用者名稱和權杖(或密碼)。
確保在 Variant 下拉式功能表中選取了 BLOCKING 選項。
點擊 Load contributors。UI 應該會凍結一段時間,然後顯示貢獻者列表。
開啟程式輸出以確保資料已載入。每次請求成功後都會記錄貢獻者列表。
實作此邏輯有不同的方式:使用 阻塞請求 或 回呼。您將把這些解決方案與使用 協同程式 的解決方案進行比較,並查看如何使用 管道 在不同協同程式之間共享資訊。
阻塞請求
您將使用 Retrofit 程式庫對 GitHub 執行 HTTP 請求。它允許請求給定組織下的存儲庫列表以及每個存儲庫的貢獻者列表:
interface GitHubService {
@GET("orgs/{org}/repos?per_page=100")
fun getOrgReposCall(
@Path("org") org: String
): Call<List<Repo>>
@GET("repos/{owner}/{repo}/contributors?per_page=100")
fun getRepoContributorsCall(
@Path("owner") owner: String,
@Path("repo") repo: String
): Call<List<User>>
}loadContributorsBlocking() 函式使用此 API 來獲取給定組織的貢獻者列表。
開啟
src/tasks/Request1Blocking.kt查看其實作:kotlinfun loadContributorsBlocking( service: GitHubService, req: RequestData ): List<User> { val repos = service .getOrgReposCall(req.org) // #1 .execute() // #2 .also { logRepos(req, it) } // #3 .body() ?: emptyList() // #4 return repos.flatMap { repo -> service .getRepoContributorsCall(req.org, repo.name) // #1 .execute() // #2 .also { logUsers(repo, it) } // #3 .bodyList() // #4 }.aggregate() }- 首先,您獲取給定組織下的存儲庫列表並將其儲存在
repos列表中。接著針對每個存儲庫請求貢獻者列表,最後將所有列表合併為一個最終的貢獻者列表。 getOrgReposCall()與getRepoContributorsCall()都會回傳*Call類別的執行個體 (#1)。此時尚未發送請求。- 接著調用
*Call.execute()來執行請求 (#2)。execute()是一個同步呼叫,會阻塞底層執行緒。 - 當您收到回應時,會透過呼叫特定的
logRepos()與logUsers()函式來記錄結果 (#3)。如果 HTTP 回應包含錯誤,該錯誤將在此處被記錄。 - 最後,獲取回應的主體,其中包含您需要的資料。在本教學中,若發生錯誤,您將使用空列表作為結果,並記錄對應的錯誤 (
#4)。
- 首先,您獲取給定組織下的存儲庫列表並將其儲存在
為了避免重複寫
.body() ?: emptyList(),宣告了一個擴充函式bodyList():kotlinfun <T> Response<List<T>>.bodyList(): List<T> { return body() ?: emptyList() }再次執行程式,並查看 IntelliJ IDEA 中的系統輸出。它應該類似於:
text1770 [AWT-EventQueue-0] INFO Contributors - kotlin: loaded 40 repos 2025 [AWT-EventQueue-0] INFO Contributors - kotlin-examples: loaded 23 contributors 2229 [AWT-EventQueue-0] INFO Contributors - kotlin-koans: loaded 45 contributors ...- 每行第一個項目是程式啟動後經過的毫秒數,接著是方括號內的執行緒名稱。您可以看到載入請求是從哪個執行緒呼叫的。
- 每行最後一個項目是實際訊息:載入了多少個存儲庫或貢獻者。
此日誌輸出說明所有結果都是從主執行緒記錄的。當您使用 BLOCKING 選項執行程式碼時,視窗會凍結且在載入完成前不會對輸入做出反應。所有請求都與呼叫
loadContributorsBlocking()的執行緒在同一個執行緒中執行,即主 UI 執行緒(在 Swing 中是 AWT 事件指派執行緒)。這個主執行緒變得阻塞,這就是 UI 凍結的原因:
載入貢獻者列表後,結果會更新。
在
src/contributors/Contributors.kt中,找到負責選擇如何載入貢獻者的loadContributors()函式,並查看loadContributorsBlocking()是如何被呼叫的:kotlinwhen (getSelectedVariant()) { BLOCKING -> { // 阻塞 UI 執行緒 val users = loadContributorsBlocking(service, req) updateResults(users, startTime) } }updateResults()呼叫緊接在loadContributorsBlocking()呼叫之後。updateResults()會更新 UI,因此它必須始終從 UI 執行緒呼叫。- 由於
loadContributorsBlocking()也是從 UI 執行緒呼叫的,因此 UI 執行緒會變得阻塞,UI 也會隨之凍結。
任務 1
第一個任務幫助您熟悉任務領域。目前,每個貢獻者的名稱會重複出現多次,每參加一個專案就會出現一次。實作 aggregate() 函式來合併使用者,使每個貢獻者僅被加入一次。User.contributions 屬性應包含該使用者在「所有」專案中的貢獻總數。產生的列表應根據貢獻次數降冪排序。
開啟 src/tasks/Aggregation.kt 並實作 List<User>.aggregate() 函式。使用者應依其總貢獻次數排序。
對應的測試檔案 test/tasks/AggregationKtTest.kt 顯示了預期結果的範例。
您可以使用 IntelliJ IDEA 快速鍵
Ctrl+Shift+T/⇧ ⌘ T在原始碼和測試類別之間自動跳轉。
實作此任務後,「kotlin」組織的結果列表應類似於下圖:
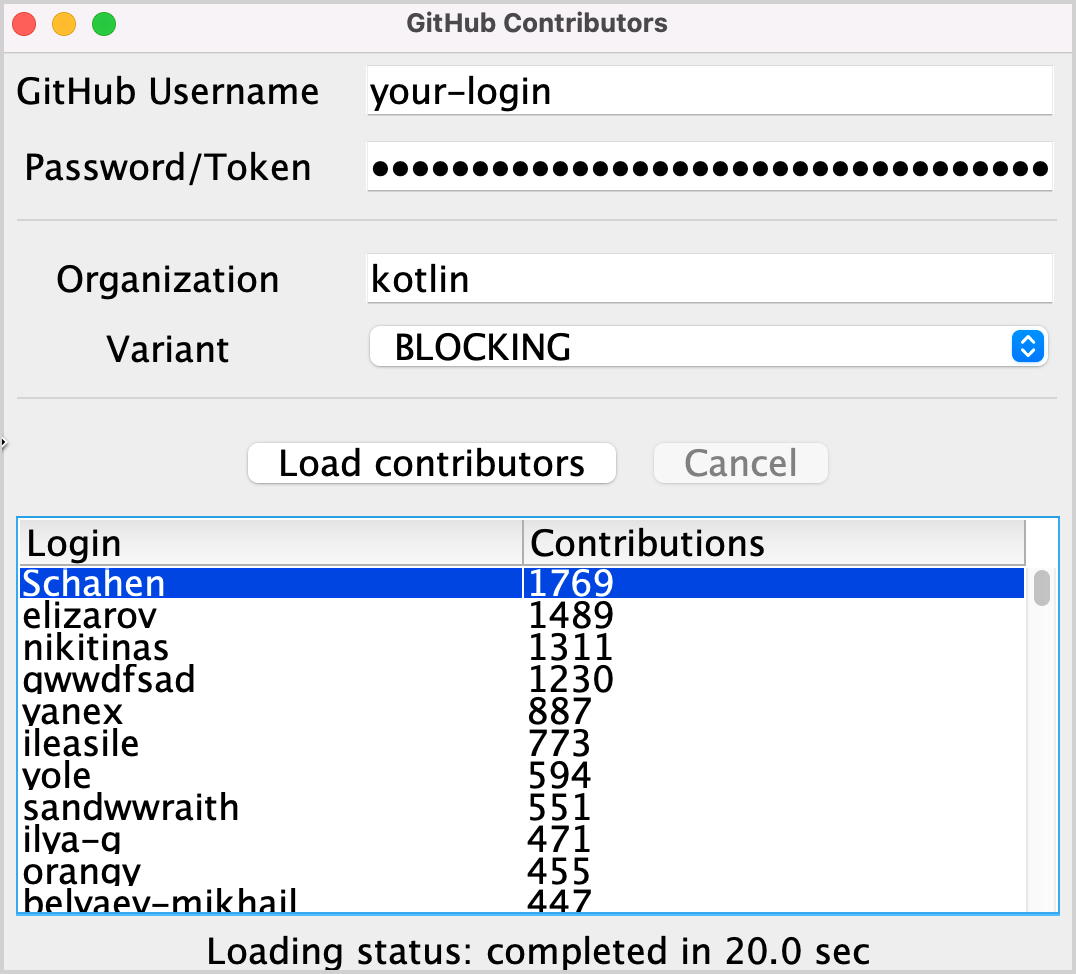
任務 1 的解答
若要按登入名稱分組使用者,請使用
groupBy(),它會回傳一個從登入名稱到該使用者在不同存儲庫中所有出現情況的對應表(map)。對於每個 map 項目,計算每位使用者的總貢獻次數,並根據給定名稱和總貢獻次數建立一個新的
User類別執行個體。對產生的列表進行降冪排序:
kotlinfun List<User>.aggregate(): List<User> = groupBy { it.login } .map { (login, group) -> User(login, group.sumOf { it.contributions }) } .sortedByDescending { it.contributions }
另一種解決方案是使用 groupingBy() 函式來取代 groupBy()。
回呼
之前的解決方案雖然可行,但會阻塞執行緒並導致 UI 凍結。避免這種情況的一種傳統方法是使用「回呼(callback)」。
您可以將原本應該在操作完成後立即呼叫的程式碼提取到一個單獨的回呼(通常是 Lambda)中,並將該 Lambda 傳遞給呼叫者,以便稍後呼叫。
為了讓 UI 保持回應,您可以將整個計算移動到一個單獨的執行緒,或者切換到使用回呼而非阻塞呼叫的 Retrofit API。
使用背景執行緒
開啟
src/tasks/Request2Background.kt並查看其實作。首先,整個計算被移動到不同的執行緒。thread()函式會啟動一個新執行緒:kotlinthread { loadContributorsBlocking(service, req) }現在所有的載入工作都已移動到單獨的執行緒,主執行緒是空閒的,可以處理其他任務:

loadContributorsBackground()函式的簽章發生了變化。它接受一個updateResults()回呼作為最後一個引數,以便在所有載入完成後呼叫它:kotlinfun loadContributorsBackground( service: GitHubService, req: RequestData, updateResults: (List<User>) -> Unit )現在呼叫
loadContributorsBackground()時,updateResults()呼叫會放在回呼中,而不是像以前那樣緊接著呼叫:kotlinloadContributorsBackground(service, req) { users -> SwingUtilities.invokeLater { updateResults(users, startTime) } }透過呼叫
SwingUtilities.invokeLater,您可以確保更新結果的updateResults()呼叫發生在主 UI 執行緒(AWT 事件指派執行緒)上。
然而,如果您嘗試透過 BACKGROUND 選項載入貢獻者,您會發現列表雖然更新了,但沒有顯示任何內容。
任務 2
修正 src/tasks/Request2Background.kt 中的 loadContributorsBackground() 函式,以便在 UI 中顯示結果列表。
任務 2 的解答
如果您嘗試載入貢獻者,您可以在日誌中看到貢獻者已載入,但結果未顯示。要修正此問題,請對產生的使用者列表呼叫 updateResults():
thread {
updateResults(loadContributorsBlocking(service, req))
}請務必明確呼叫回呼中傳遞的邏輯。否則什麼都不會發生。
使用 Retrofit 回呼 API
在之前的解決方案中,雖然將整個載入邏輯移動到了背景執行緒,但這仍然不是資源的最佳利用方式。所有的載入請求都是循序進行的,且執行緒在等待載入結果時是被阻塞的,而它本可以處理其他任務。具體來說,執行緒本可以開始載入另一個請求,以便更早獲得完整結果。
處理每個存儲庫的資料應分為兩個部分:載入和處理產生的回應。第二個「處理」部分應該提取到一個回呼中。
這樣,在收到前一個存儲庫的結果(並呼叫對應的回呼)之前,就可以開始下一個存儲庫的載入:

Retrofit 回呼 API 可以幫助實現這一點。Call.enqueue() 函式啟動一個 HTTP 請求並接受一個回呼作為引數。在此回呼中,您需要指定每個請求後需要執行的操作。
開啟 src/tasks/Request3Callbacks.kt 查看使用此 API 的 loadContributorsCallbacks() 實作:
fun loadContributorsCallbacks(
service: GitHubService, req: RequestData,
updateResults: (List<User>) -> Unit
) {
service.getOrgReposCall(req.org).onResponse { responseRepos -> // #1
logRepos(req, responseRepos)
val repos = responseRepos.bodyList()
val allUsers = mutableListOf<User>()
for (repo in repos) {
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers -> // #2
logUsers(repo, responseUsers)
val users = responseUsers.bodyList()
allUsers += users
}
}
}
// TODO: 為什麼這段程式碼不起作用?該如何修復?
updateResults(allUsers.aggregate())
}- 為了方便起見,此程式碼片段使用了同一檔案中宣告的
onResponse()擴充函式。它接受一個 Lambda 作為引數,而不是物件運算式。 - 處理回應的邏輯被提取到回呼中:對應的 Lambda 從第
#1行和第#2行開始。
然而,提供的解決方案不起作用。如果您執行程式並選擇 CALLBACKS 選項載入貢獻者,您將看到沒有顯示任何內容。但是,來自 Request3CallbacksKtTest 的測試會立即回傳成功通過的結果。
思考一下為什麼給定的程式碼沒有如預期運作,並嘗試修復它,或者查看下面的解決方案。
任務 3 (選修)
重寫 src/tasks/Request3Callbacks.kt 檔案中的程式碼,以便顯示載入的貢獻者列表。
任務 3 的第一次嘗試解決方案
在目前的解決方案中,許多請求是並行啟動的,這減少了總載入時間。然而,結果並未載入。這是因為 updateResults() 回呼在所有載入請求啟動後立即被呼叫,此時 allUsers 列表尚未填入資料。
您可以嘗試進行如下修改來修復此問題:
val allUsers = mutableListOf<User>()
for ((index, repo) in repos.withIndex()) { // #1
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers ->
logUsers(repo, responseUsers)
val users = responseUsers.bodyList()
allUsers += users
if (index == repos.lastIndex) { // #2
updateResults(allUsers.aggregate())
}
}
}- 首先,您使用索引 (
#1) 遍歷存儲庫列表。 - 接著,在每個回呼中,檢查是否為最後一次反覆運算 (
#2)。 - 如果是這種情況,則更新結果。
然而,這段程式碼也無法達到我們的目標。嘗試自己找出答案,或查看下面的解決方案。
任務 3 的第二次嘗試解決方案
由於載入請求是並行啟動的,因此無法保證最後一個請求的結果會最後到達。結果可以按任何順序返回。
因此,如果您將目前的索引與 lastIndex 比較作為完成條件,您可能會丟失某些存儲庫的結果。
如果處理最後一個存儲庫的請求比之前的一些請求返回得更快(這很可能發生),那麼所有耗時較長的請求結果都將丟失。
修正此問題的一種方法是引入一個索引並檢查是否所有存儲庫都已處理完畢:
val allUsers = Collections.synchronizedList(mutableListOf<User>())
val numberOfProcessed = AtomicInteger()
for (repo in repos) {
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers ->
logUsers(repo, responseUsers)
val users = responseUsers.bodyList()
allUsers += users
if (numberOfProcessed.incrementAndGet() == repos.size) {
updateResults(allUsers.aggregate())
}
}
}這段程式碼使用了列表的同步版本和 AtomicInteger(),因為一般來說,無法保證處理 getRepoContributors() 請求的不同回呼總是在同一個執行緒中呼叫。
任務 3 的第三次嘗試解決方案
更好的解決方案是使用 CountDownLatch 類別。它儲存一個以存儲庫數量初始化的計數器。處理完每個存儲庫後,該計數器會遞減。然後它會等待計數器減至零,再更新結果:
val countDownLatch = CountDownLatch(repos.size)
for (repo in repos) {
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers ->
// 處理存儲庫
countDownLatch.countDown()
}
}
countDownLatch.await()
updateResults(allUsers.aggregate())結果接著從主執行緒更新。這比將邏輯委派給子執行緒更直接。
在審查了這三種解決方案嘗試後,您可以看到使用回呼撰寫正確的程式碼是非瑣細且容易出錯的,特別是當涉及多個底層執行緒和同步時。
作為額外的練習,您可以使用 RxJava 程式庫透過響應式方法實作相同的邏輯。所有必要的相依性和使用 RxJava 的解決方案都可以在單獨的
rx分支中找到。您也可以完成本教學並實作或檢查建議的 Rx 版本以進行適當的比較。
暫停函式
您可以使用暫停函式實作相同的邏輯。定義 API 呼叫為 暫停函式,而不是回傳 Call<List<Repo>>,如下所示:
interface GitHubService {
@GET("orgs/{org}/repos?per_page=100")
suspend fun getOrgRepos(
@Path("org") org: String
): List<Repo>
}getOrgRepos()被定義為suspend函式。當您使用暫停函式執行請求時,底層執行緒不會被阻塞。關於其運作方式的更多細節將在稍後的章節中介紹。getOrgRepos()直接回傳結果,而不是回傳Call。如果結果不成功,則會拋出例外。
或者,Retrofit 允許回傳包裝在 Response 中的結果。在這種情況下,會提供結果主體,並且可以手動檢查錯誤。本教學使用回傳 Response 的版本。
在 src/contributors/GitHubService.kt 中,將以下宣告加入 GitHubService 介面:
interface GitHubService {
// getOrgReposCall & getRepoContributorsCall 宣告
@GET("orgs/{org}/repos?per_page=100")
suspend fun getOrgRepos(
@Path("org") org: String
): Response<List<Repo>>
@GET("repos/{owner}/{repo}/contributors?per_page=100")
suspend fun getRepoContributors(
@Path("owner") owner: String,
@Path("repo") repo: String
): Response<List<User>>
}任務 4
您的任務是更改載入貢獻者的函式程式碼,以使用兩個新的暫停函式:getOrgRepos() 和 getRepoContributors()。新的 loadContributorsSuspend() 函式被標記為 suspend 以使用新的 API。
暫停函式不能在任何地方呼叫。從
loadContributorsBlocking()呼叫暫停函式會導致錯誤,訊息為 "Suspend function 'getOrgRepos' should be called only from a coroutine or another suspend function"(暫停函式 'getOrgRepos' 只能從協同程式或其他暫停函式中呼叫)。
- 將
src/tasks/Request1Blocking.kt中定義的loadContributorsBlocking()實作複製到src/tasks/Request4Suspend.kt中定義的loadContributorsSuspend()中。 - 修改程式碼,以便使用新的暫停函式來取代那些回傳
Call的函式。 - 透過選擇 SUSPEND 選項執行程式,並確保在執行 GitHub 請求時 UI 仍然具有回應。
任務 4 的解答
將 .getOrgReposCall(req.org).execute() 替換為 .getOrgRepos(req.org),並對第二個 "contributors" 請求重複相同的替換:
suspend fun loadContributorsSuspend(service: GitHubService, req: RequestData): List<User> {
val repos = service
.getOrgRepos(req.org)
.also { logRepos(req, it) }
.bodyList()
return repos.flatMap { repo ->
service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
}.aggregate()
}loadContributorsSuspend()應定義為suspend函式。- 您不再需要呼叫之前回傳
Response的execute,因為現在 API 函式會直接回傳Response。請注意,此細節特定於 Retrofit 程式庫。對於其他程式庫,API 會有所不同,但概念是一樣的。
協同程式
使用暫停函式的程式碼看起來與「阻塞」版本相似。與阻塞版本的主要區別在於,協同程式是被暫停,而不是阻塞執行緒:
block -> suspend
thread -> coroutine協同程式通常被稱為輕量級執行緒,因為您可以在協同程式上執行程式碼,類似於在執行緒上執行程式碼的方式。以前會造成阻塞(且必須避免)的操作現在可以改為暫停協同程式。
啟動新的協同程式
如果您查看 src/contributors/Contributors.kt 中如何使用 loadContributorsSuspend(),您可以看到它是在 launch 內部被呼叫的。launch 是一個程式庫函式,它接受一個 Lambda 作為引數:
launch {
val users = loadContributorsSuspend(req)
updateResults(users, startTime)
}在這裡,launch 啟動了一個負責載入資料並顯示結果的新計算。該計算是可暫停的 —— 在執行網路請求時,它會被暫停並釋放底層執行緒。當網路請求返回結果時,計算會恢復。
這種可暫停的計算被稱為「協同程式(coroutine)」。因此,在這種情況下,launch「啟動了一個新的協同程式」,負責載入資料並顯示結果。
協同程式執行於執行緒之上,且可以被暫停。當協同程式被暫停時,對應的計算會暫停,從執行緒中移除並儲存在記憶體中。與此同時,執行緒是空閒的,可以被其他任務佔用:
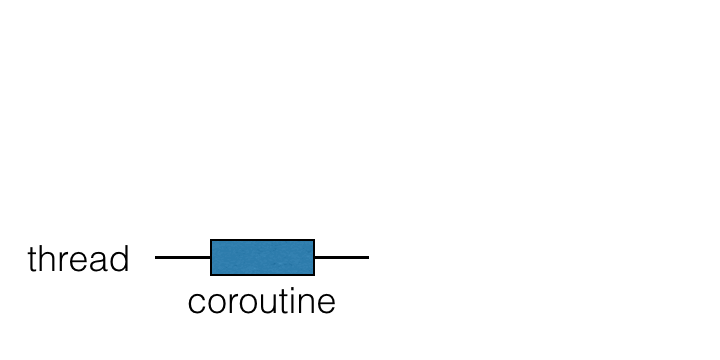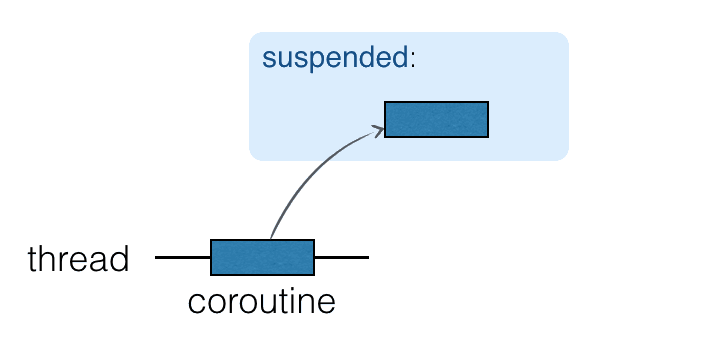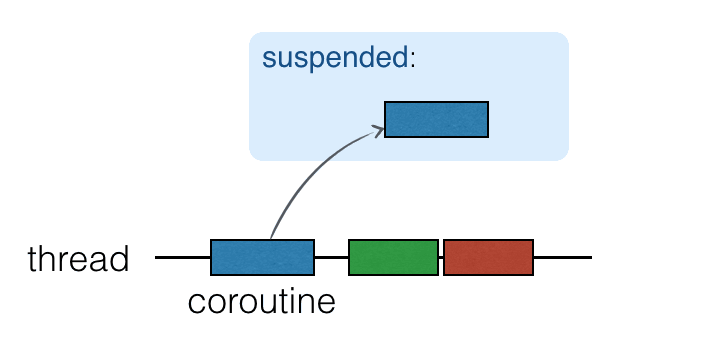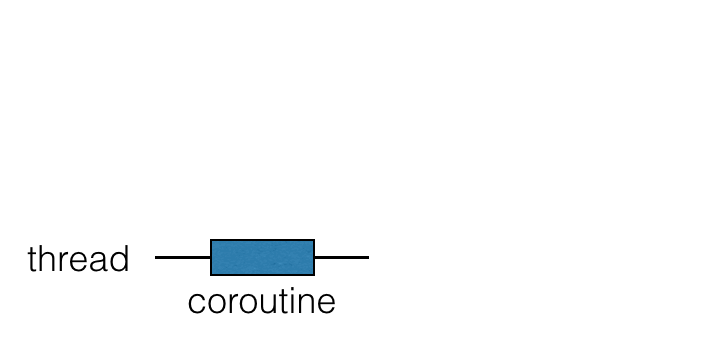
當計算準備好繼續時,它會返回到一個執行緒(不一定是同一個執行緒)。
在 loadContributorsSuspend() 範例中,每個 "contributors" 請求現在使用暫停機制等待結果。首先,發送新請求。接著,在等待回應時,由 launch 函式啟動的整個 "load contributors" 協同程式會被暫停。
只有在收到對應的回應後,協同程式才會恢復:
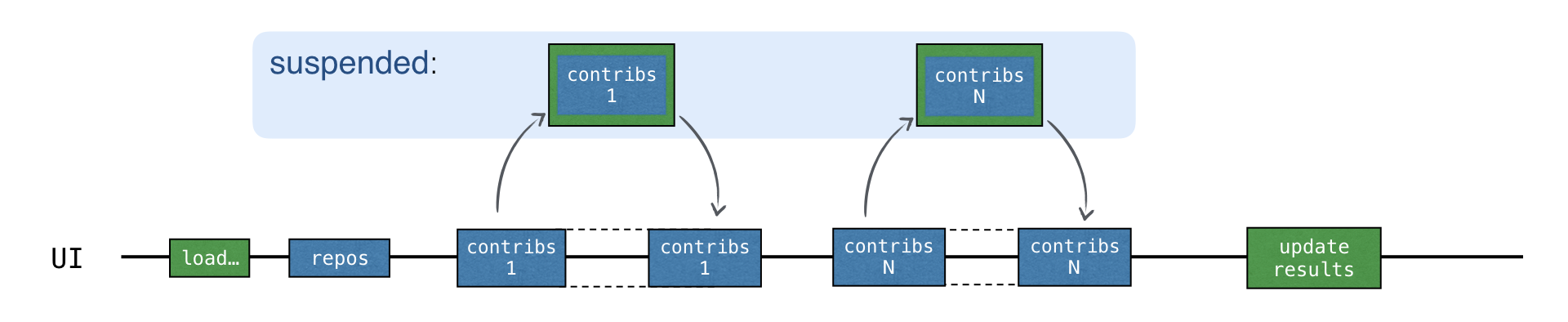
在等待接收回應時,執行緒可以自由地被其他任務佔用。儘管所有請求都在主 UI 執行緒上發生,UI 仍保持回應:
使用 SUSPEND 選項執行程式。日誌確認所有請求都已發送到主 UI 執行緒:
text2538 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin: loaded 30 repos 2729 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - ts2kt: loaded 11 contributors 3029 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin-koans: loaded 45 contributors ... 11252 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin-coroutines-workshop: loaded 1 contributors日誌可以顯示對應程式碼是在哪個協同程式上執行的。要啟用它,請開啟 Run | Edit configurations 並加入
-Dkotlinx.coroutines.debugVM 選項: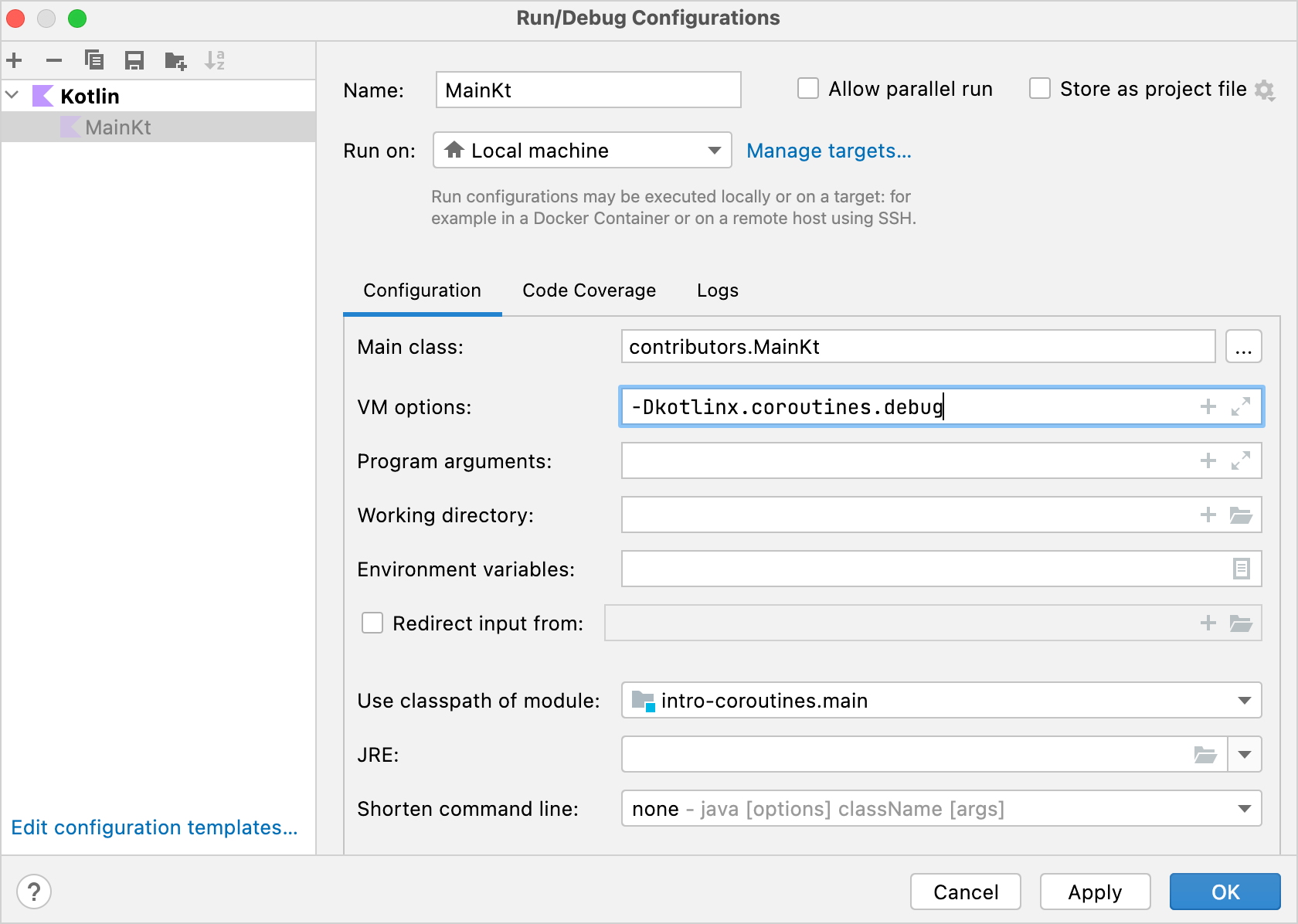
使用此選項執行
main()時,協同程式名稱將附加到執行緒名稱。您也可以修改執行所有 Kotlin 檔案的樣板,並預設啟用此選項。
現在所有程式碼都在一個協同程式上執行,即上面提到的 "load contributors" 協同程式,標記為 @coroutine#1。在等待結果時,您不應重用執行緒來發送其他請求,因為程式碼是循序撰寫的。只有在收到前一個結果時才會發送新請求。
暫停函式公平地對待執行緒,不會為了「等待」而阻塞它。然而,這還沒有帶來任何並行性。
並行
Kotlin 協同程式比執行緒更節省資源。每當您想要非同步啟動新的計算時,可以改為建立一個新的協同程式。
要啟動新的協同程式,請使用主要的「協同程式建構器(coroutine builders)」之一:launch、async 或 runBlocking。不同的程式庫可以定義額外的協同程式建構器。
async 會啟動一個新的協同程式並回傳一個 Deferred 物件。Deferred 代表一個在其他地方被稱為 Future 或 Promise 的概念。它儲存一個計算,但它「延遲(defer)」了您獲得最終結果的時刻;它「承諾(promise)」在「未來」的某個時間提供結果。
async 和 launch 之間的主要區別在於,launch 用於啟動預期不會回傳特定結果的計算。launch 回傳一個代表協同程式的 Job。可以透過呼叫 Job.join() 來等待它完成。
Deferred 是一個擴充 Job 的泛型型別。async 呼叫可以回傳 Deferred<Int> 或 Deferred<CustomType>,具體取決於 Lambda 回傳的內容(Lambda 內的最後一個運算式即為結果)。
若要獲取協同程式的結果,您可以對 Deferred 執行個體呼叫 await()。在等待結果時,呼叫此 await() 的協同程式會被暫停:
import kotlinx.coroutines.*
fun main() = runBlocking {
val deferred: Deferred<Int> = async {
loadData()
}
println("waiting...")
println(deferred.await())
}
suspend fun loadData(): Int {
println("loading...")
delay(1000L)
println("loaded!")
return 42
}runBlocking 被用作正規函式與暫停函式之間,或是阻塞世界與非阻塞世界之間的橋樑。它充當啟動最上層主協同程式的適配器。它主要用於 main() 函式和測試中。
觀看此影片以更深入地了解協同程式。
如果有一個 deferred 物件列表,您可以呼叫 awaitAll() 來等待它們所有人的結果:
import kotlinx.coroutines.*
fun main() = runBlocking {
val deferreds: List<Deferred<Int>> = (1..3).map {
async {
delay(1000L * it)
println("Loading $it")
it
}
}
val sum = deferreds.awaitAll().sum()
println("$sum")
}當每個 "contributors" 請求都在一個新的協同程式中啟動時,所有請求都會非同步啟動。在收到前一個請求的結果之前,就可以發送新的請求:
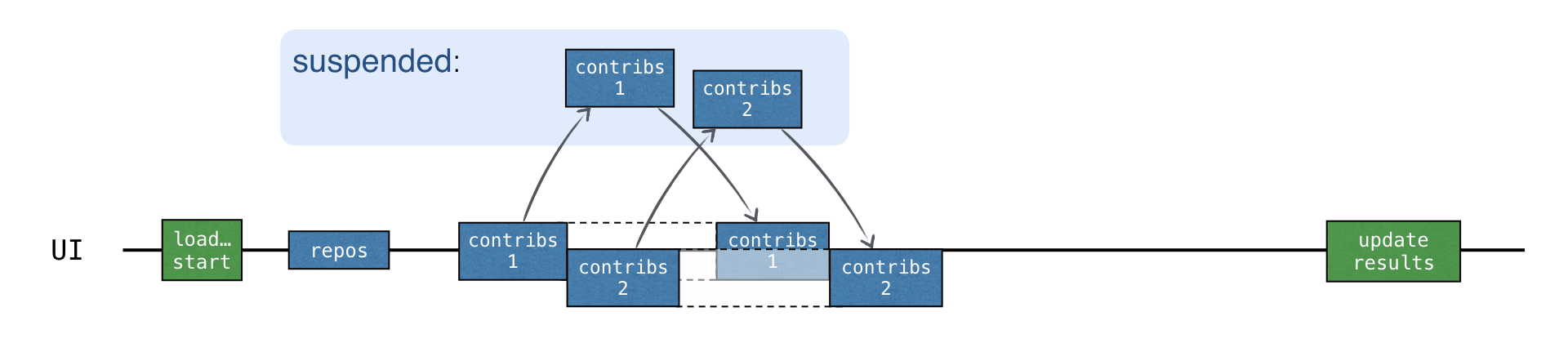
總載入時間與 CALLBACKS 版本大約相同,但它不需要任何回呼。此外,async 在程式碼中明確強調了哪些部分是並行執行的。
任務 5
在 Request5Concurrent.kt 檔案中,使用先前的 loadContributorsSuspend() 函式實作 loadContributorsConcurrent() 函式。
任務 5 的提示
您只能在協同程式作用域內啟動新的協同程式。將 loadContributorsSuspend() 中的內容複製到 coroutineScope 呼叫中,以便在那裡呼叫 async 函式:
suspend fun loadContributorsConcurrent(
service: GitHubService,
req: RequestData
): List<User> = coroutineScope {
// ...
}根據以下方案建立您的解決方案:
val deferreds: List<Deferred<List<User>>> = repos.map { repo ->
async {
// 為每個存儲庫載入貢獻者
}
}
deferreds.awaitAll() // List<List<User>>任務 5 的解答
將每個 "contributors" 請求包裝在 async 中,以建立與存儲庫數量一樣多的協同程式。async 回傳 Deferred<List<User>>。這不是問題,因為建立新的協同程式並不太消耗資源,所以您可以根據需要建立任意多個。
您不能再使用
flatMap,因為map的結果現在是一個Deferred物件列表,而不是列表的列表。awaitAll()回傳List<List<User>>,因此呼叫flatten().aggregate()來獲取結果:kotlinsuspend fun loadContributorsConcurrent( service: GitHubService, req: RequestData ): List<User> = coroutineScope { val repos = service .getOrgRepos(req.org) .also { logRepos(req, it) } .bodyList() val deferreds: List<Deferred<List<User>>> = repos.map { repo -> async { service.getRepoContributors(req.org, repo.name) .also { logUsers(repo, it) } .bodyList() } } deferreds.awaitAll().flatten().aggregate() }執行程式碼並檢查日誌。所有協同程式仍然在主 UI 執行緒上執行,因為尚未採用多執行緒,但您已經可以看到並行執行協同程式的好處。
若要將此程式碼更改為在通用執行緒池的不同執行緒上執行 "contributors" 協同程式,請指定
Dispatchers.Default作為async函式的上下文引數:kotlinasync(Dispatchers.Default) { }CoroutineDispatcher決定對應的協同程式應在哪些執行緒上執行。如果您不指定一個作為引數,async將使用來自外部作用域的排程器(dispatcher)。Dispatchers.Default代表 JVM 上的共用執行緒池。此池提供了一種平行執行的方法。它由與 CPU 核心數一樣多的執行緒組成,但如果只有一個核心,它仍然會有兩個執行緒。
修改
loadContributorsConcurrent()函式中的程式碼,以便在通用執行緒池的不同執行緒上啟動新的協同程式。此外,在發送請求之前加入額外的日誌記錄:kotlinasync(Dispatchers.Default) { log("starting loading for ${repo.name}") service.getRepoContributors(req.org, repo.name) .also { logUsers(repo, it) } .bodyList() }再次執行程式。在日誌中,您可以看到每個協同程式可以在執行緒池中的一個執行緒上啟動,並在另一個執行緒上恢復:
text1946 [DefaultDispatcher-worker-2 @coroutine#4] INFO Contributors - starting loading for kotlin-koans 1946 [DefaultDispatcher-worker-3 @coroutine#5] INFO Contributors - starting loading for dokka 1946 [DefaultDispatcher-worker-1 @coroutine#3] INFO Contributors - starting loading for ts2kt ... 2178 [DefaultDispatcher-worker-1 @coroutine#4] INFO Contributors - kotlin-koans: loaded 45 contributors 2569 [DefaultDispatcher-worker-1 @coroutine#5] INFO Contributors - dokka: loaded 36 contributors 2821 [DefaultDispatcher-worker-2 @coroutine#3] INFO Contributors - ts2kt: loaded 11 contributors例如,在此日誌節選中,
coroutine#4在worker-2執行緒上啟動,並在worker-1執行緒上繼續。
在 src/contributors/Contributors.kt 中,檢查 CONCURRENT 選項的實作:
要僅在主 UI 執行緒上執行協同程式,請指定
Dispatchers.Main作為引數:kotlinlaunch(Dispatchers.Main) { updateResults() }- 如果您在主執行緒上啟動新的協同程式時主執行緒正忙,該協同程式將被暫停並排定在該執行緒上執行。協同程式僅在執行緒空閒時才會恢復。
- 使用來自外部作用域的排程器被認為是良好的做法,而不是在每個端點上明確指定它。如果您在定義
loadContributorsConcurrent()時不傳遞Dispatchers.Default作為引數,您可以在任何上下文中呼叫此函式:使用Default排程器、使用主 UI 執行緒或使用自訂排程器。 - 正如您稍後將看到的,從測試中呼叫
loadContributorsConcurrent()時,您可以在帶有TestDispatcher的上下文中呼叫它,這簡化了測試。這使得該解決方案更加靈活。
要在呼叫端指定排程器,請對專案進行以下更改,同時讓
loadContributorsConcurrent在繼承的上下文中啟動協同程式:kotlinlaunch(Dispatchers.Default) { val users = loadContributorsConcurrent(service, req) withContext(Dispatchers.Main) { updateResults(users, startTime) } }updateResults()應在主 UI 執行緒上呼叫,因此您在Dispatchers.Main的上下文中呼叫它。withContext()使用指定的協同程式上下文呼叫給定的程式碼,並暫停直到它完成並回傳結果。另一種但更冗長的方法是啟動一個新的協同程式並明確等待(透過暫停)直到它完成:launch(context) { ... }.join()。
執行程式碼並確保協同程式在執行緒池中的執行緒上執行。
結構化並行
- 協同程式作用域 (coroutine scope) 負責不同協同程式之間的結構和父子關係。新的協同程式通常需要在作用域內啟動。
- 協同程式上下文 (coroutine context) 儲存用於執行給定協同程式的額外技術資訊,例如協同程式自訂名稱,或指定協同程式應排定在哪些執行緒上的排程器。
當使用 launch、async 或 runBlocking 啟動新的協同程式時,它們會自動建立對應的作用域。所有這些函式都接受一個帶有接收器的 Lambda 作為引數,而 CoroutineScope 是隱含的接收器型別:
launch { /* this: CoroutineScope */ }- 新的協同程式只能在作用域內啟動。
launch和async被宣告為CoroutineScope的擴充功能,因此呼叫它們時必須始終傳遞隱含或明確的接收器。- 由
runBlocking啟動的協同程式是唯一的例外,因為runBlocking被定義為最上層函式。但因為它會阻塞目前執行緒,所以它主要用於main()函式和測試中作為橋樑函式。
在 runBlocking、launch 或 async 內部的嵌套協同程式會自動在作用域內啟動:
import kotlinx.coroutines.*
fun main() = runBlocking { /* this: CoroutineScope */
launch { /* ... */ }
// 等同於:
this.launch { /* ... */ }
}當您在 runBlocking 內部呼叫 launch 時,它是作為 CoroutineScope 型別隱含接收器的擴充功能被呼叫的。或者,您可以明確寫成 this.launch。
嵌套協同程式(在此範例中由 launch 啟動)可以被視為外部協同程式(由 runBlocking 啟動)的子項。這種「父子」關係透過作用域運作;子協同程式是從對應於父協同程式的作用域啟動的。
可以透過使用 coroutineScope 函式來建立新作用域而不啟動新協同程式。要在無法存取外部作用域的 suspend 函式中以結構化方式啟動新協同程式,您可以建立一個新的協同程式作用域,它會自動成為呼叫該 suspend 函式的外部作用域的子項。loadContributorsConcurrent() 是一個很好的例子。
您也可以使用 GlobalScope.async 或 GlobalScope.launch 從全域作用域啟動新的協同程式。這將建立一個最上層的「獨立」協同程式。
協同程式結構背後的機制被稱為 結構化並行 (structured concurrency)。與全域作用域相比,它提供了以下好處:
- 作用域通常負責子協同程式,子協同程式的生命週期與作用域的生命週期掛鉤。
- 如果發生錯誤或使用者改變主意決定撤銷操作,作用域可以自動取消子協同程式。
- 作用域會自動等待所有子協同程式完成。因此,如果作用域對應於一個協同程式,則父協同程式在其實作作用域中啟動的所有協同程式完成之前不會完成。
使用 GlobalScope.async 時,沒有結構將多個協同程式綁定到一個較小的作用域。從全域作用域啟動的協同程式都是獨立的 —— 它們的生命週期僅受整個應用程式生命週期的限制。雖然可以儲存對從全域作用域啟動的協同程式的參照,並等待其完成或明確取消它,但這不會像結構化並行那樣自動發生。
取消貢獻者的載入
建立兩個版本的載入貢獻者列表函式。比較當您嘗試取消父協同程式時這兩個版本的行為。第一個版本將使用 coroutineScope 來啟動所有子協同程式,而第二個版本將使用 GlobalScope。
在
Request5Concurrent.kt中,向loadContributorsConcurrent()函式加入 3 秒延遲:kotlinsuspend fun loadContributorsConcurrent( service: GitHubService, req: RequestData ): List<User> = coroutineScope { // ... async { log("starting loading for ${repo.name}") delay(3000) // 載入存儲庫貢獻者 } // ... }延遲會影響所有發送請求的協同程式,以便在協同程式啟動後但在發送請求之前有足夠的時間取消載入。
建立載入函式的第二個版本:將
loadContributorsConcurrent()的實作複製到Request5NotCancellable.kt中的loadContributorsNotCancellable(),然後移除新coroutineScope的建立。現在
async呼叫無法解析,因此改用GlobalScope.async啟動它們:kotlinsuspend fun loadContributorsNotCancellable( service: GitHubService, req: RequestData ): List<User> { // #1 // ... GlobalScope.async { // #2 log("starting loading for ${repo.name}") // 載入存儲庫貢獻者 } // ... return deferreds.awaitAll().flatten().aggregate() // #3 }- 該函式現在直接回傳結果,而不是作為 Lambda 內的最後一個運算式(第
#1行和第#3行)。 - 所有 "contributors" 協同程式都在
GlobalScope中啟動,而不是作為協同程式作用域的子項(第#2行)。
- 該函式現在直接回傳結果,而不是作為 Lambda 內的最後一個運算式(第
執行程式並選擇 CONCURRENT 選項來載入貢獻者。
等到所有 "contributors" 協同程式都啟動後,點擊 Cancel。日誌顯示沒有新結果,這意味著所有請求確實都被取消了:
text2896 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin: loaded 40 repos 2901 [DefaultDispatcher-worker-2 @coroutine#4] INFO Contributors - starting loading for kotlin-koans ... 2909 [DefaultDispatcher-worker-5 @coroutine#36] INFO Contributors - starting loading for mpp-example /* 點擊 'cancel' */ /* 沒發送任何請求 */重複步驟 5,但這次選擇
NOT_CANCELLABLE選項:text2570 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin: loaded 30 repos 2579 [DefaultDispatcher-worker-1 @coroutine#4] INFO Contributors - starting loading for kotlin-koans ... 2586 [DefaultDispatcher-worker-6 @coroutine#36] INFO Contributors - starting loading for mpp-example /* 點擊 'cancel' */ /* 但所有請求仍然被發送: */ 6402 [DefaultDispatcher-worker-5 @coroutine#4] INFO Contributors - kotlin-koans: loaded 45 contributors ... 9555 [DefaultDispatcher-worker-8 @coroutine#36] INFO Contributors - mpp-example: loaded 8 contributors在這種情況下,沒有協同程式被取消,所有請求仍然被發送。
檢查 "contributors" 程式中是如何觸發取消的。點擊 Cancel 按鈕時,主「載入」協同程式會被明確取消,子協同程式也會自動取消:
kotlininterface Contributors { fun loadContributors() { // ... when (getSelectedVariant()) { CONCURRENT -> { launch { val users = loadContributorsConcurrent(service, req) updateResults(users, startTime) }.setUpCancellation() // #1 } } } private fun Job.setUpCancellation() { val loadingJob = this // #2 // 如果點擊了 'cancel' 按鈕,則取消載入作業: val listener = ActionListener { loadingJob.cancel() // #3 updateLoadingStatus(CANCELED) } // 向 'cancel' 按鈕新增監聽器: addCancelListener(listener) // 在載入作業完成後更新狀態並移除監聽器 } }
launch 函式回傳一個 Job 的執行個體。Job 儲存對載入所有資料並更新結果的「載入協同程式」的參照。您可以對其呼叫 setUpCancellation() 擴充函式(第 #1 行),將 Job 的執行個體作為接收器傳遞。
另一種表達方式是明確寫成:
val job = launch { }
job.setUpCancellation()- 為了提高可讀性,您可以使用新的
loadingJob變數在函式內部參照setUpCancellation()函式接收器(第#2行)。 - 接著,您可以為 Cancel 按鈕加入一個監聽器,以便在點擊它時取消
loadingJob(第#3行)。
有了結構化並行,您只需要取消父協同程式,取消就會自動傳遞給所有子協同程式。
使用外部作用域的上下文
當您在給定作用域內啟動新的協同程式時,更容易確保所有協同程式都以相同的上下文執行。如果需要,替換上下文也會容易得多。
現在是時候學習如何使用來自外部作用域的排程器了。由 coroutineScope 或協同程式建構器建立的新作用域始終繼承自外部作用域的上下文。在這種情況下,外部作用域是呼叫 suspend loadContributorsConcurrent() 函式的作用域:
launch(Dispatchers.Default) { // 外部作用域
val users = loadContributorsConcurrent(service, req)
// ...
}所有嵌套協同程式都會自動以繼承的上下文啟動。排程器是此上下文的一部分。這就是為什麼由 async 啟動的所有協同程式都會以預設排程器的上下文啟動:
suspend fun loadContributorsConcurrent(
service: GitHubService, req: RequestData
): List<User> = coroutineScope {
// 此作用域繼承了來自外部作用域的上下文
// ...
async { // 以繼承的上下文啟動嵌套協同程式
// ...
}
// ...
}有了結構化並行,您可以在建立最上層協同程式時一次性指定主要的上下文元素(如排程器)。所有嵌套協同程式隨後都會繼承該上下文,並且僅在需要時進行修改。
當您為 UI 應用程式(例如 Android)撰寫協同程式程式碼時,通常預設為最上層協同程式使用
CoroutineDispatchers.Main,然後在需要於不同執行緒執行程式碼時明確放入不同的排程器。
顯示進度
儘管某些存儲庫的資訊載入速度相當快,但使用者只有在所有資料載入後才能看到結果列表。在此之前,載入器圖示會一直轉動顯示進度,但沒有關於目前狀態或已載入哪些貢獻者的資訊。
您可以更早地顯示中間結果,並在載入每個存儲庫的資料後顯示所有貢獻者:
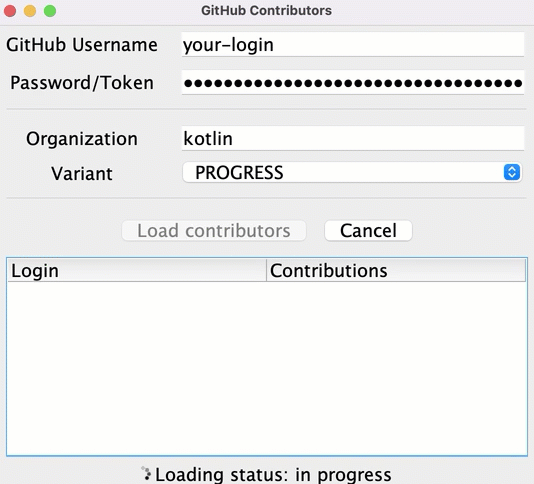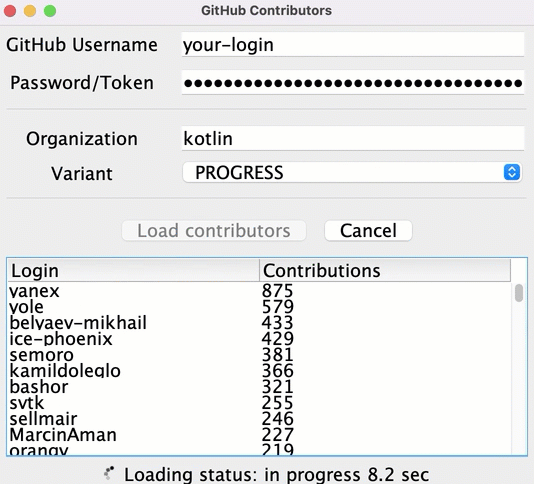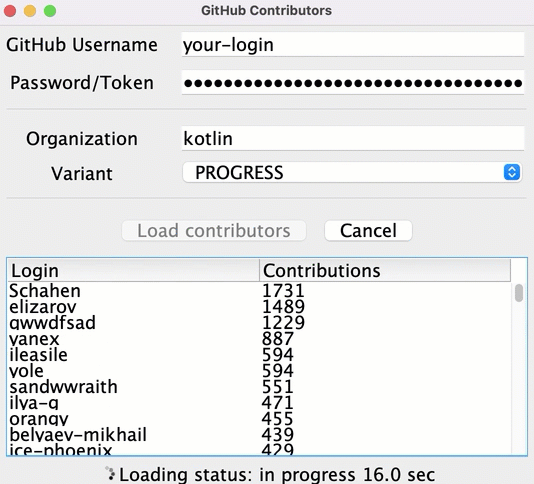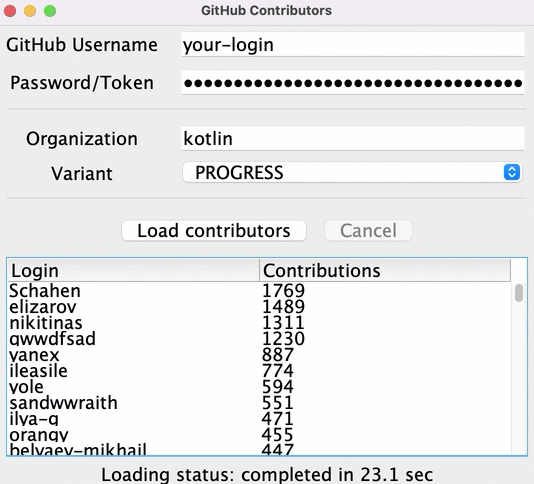
要實作此功能,在 src/tasks/Request6Progress.kt 中,您需要將更新 UI 的邏輯作為回呼傳遞,以便在每個中間狀態呼叫它:
suspend fun loadContributorsProgress(
service: GitHubService,
req: RequestData,
updateResults: suspend (List<User>, completed: Boolean) -> Unit
) {
// 載入資料
// 在中間狀態呼叫 `updateResults()`
}在 Contributors.kt 的呼叫端,針對 PROGRESS 選項傳遞回呼以從 Main 執行緒更新結果:
launch(Dispatchers.Default) {
loadContributorsProgress(service, req) { users, completed ->
withContext(Dispatchers.Main) {
updateResults(users, startTime, completed)
}
}
}updateResults()參數在loadContributorsProgress()中被宣告為suspend。必須在對應的 Lambda 引數中呼叫withContext,它是一個suspend函式。updateResults()回呼接受一個額外的布林參數作為引數,指定載入是否已完成以及結果是否為最終結果。
任務 6
在 Request6Progress.kt 檔案中,實作顯示中間進度的 loadContributorsProgress() 函式。以 Request4Suspend.kt 中的 loadContributorsSuspend() 函式為基礎。
- 使用不含並行的簡單版本;您將在下一節中加入它。
- 中間貢獻者列表應以「聚合」狀態顯示,而不僅僅是為每個存儲庫載入的使用者列表。
- 載入每個新存儲庫的資料後,每位使用者的總貢獻數應增加。
任務 6 的解答
要以「聚合」狀態儲存已載入貢獻者的中間列表,定義一個儲存使用者列表的 allUsers 變數,然後在載入每個新存儲庫的貢獻者後更新它:
suspend fun loadContributorsProgress(
service: GitHubService,
req: RequestData,
updateResults: suspend (List<User>, completed: Boolean) -> Unit
) {
val repos = service
.getOrgRepos(req.org)
.also { logRepos(req, it) }
.bodyList()
var allUsers = emptyList<User>()
for ((index, repo) in repos.withIndex()) {
val users = service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
allUsers = (allUsers + users).aggregate()
updateResults(allUsers, index == repos.lastIndex)
}
}連續 vs 並行
在每個請求完成後都會呼叫 updateResults() 回呼:
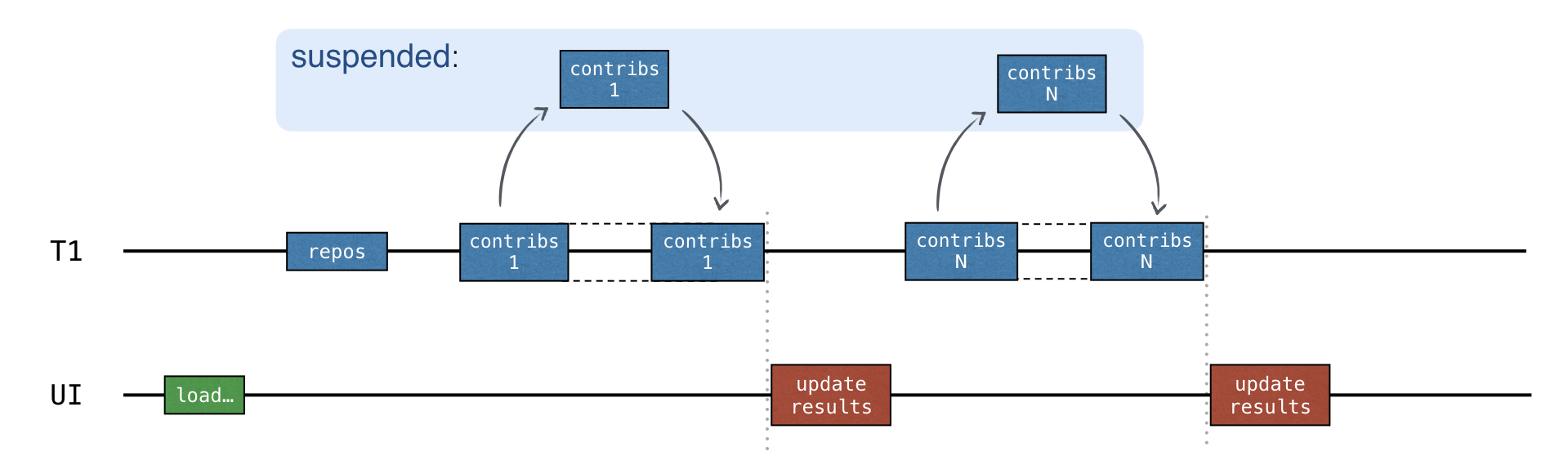
這段程式碼不包含並行。它是循序的,因此不需要同步。
最佳選擇是並行發送請求,並在收到每個存儲庫的回應後更新中間結果:
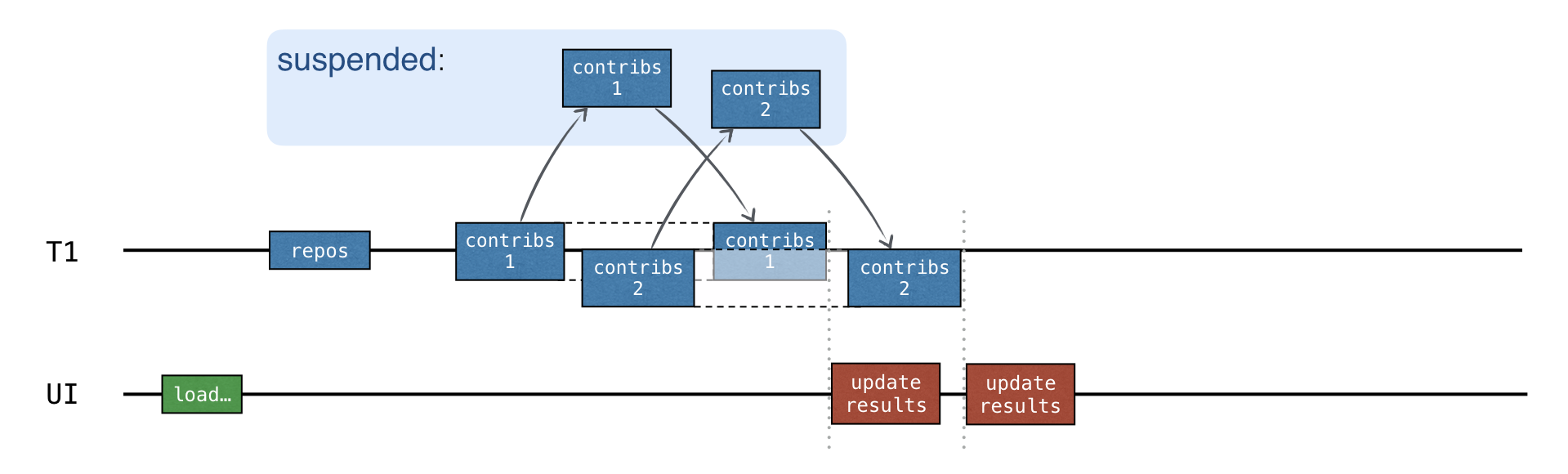
若要加入並行,請使用「管道 (channel)」。
管道
使用共享可變狀態編寫程式碼非常困難且容易出錯(就像使用回呼的解決方案一樣)。一種更簡單的方法是透過通訊而不是使用共同的可變狀態來共享資訊。協同程式可以透過 管道 (channels) 相互通訊。
管道是通訊原語,允許在協同程式之間傳遞資料。一個協同程式可以向管道 發送 (send) 一些資訊,而另一個協同程式可以從中 接收 (receive) 這些資訊:

發送(生產)資訊的協同程式通常被稱為 生產者 (producer),而接收(消費)資訊的協同程式被稱為 消費者 (consumer)。一個或多個協同程式可以向同一個管道發送資訊,一個或多個協同程式可以從中接收資料:
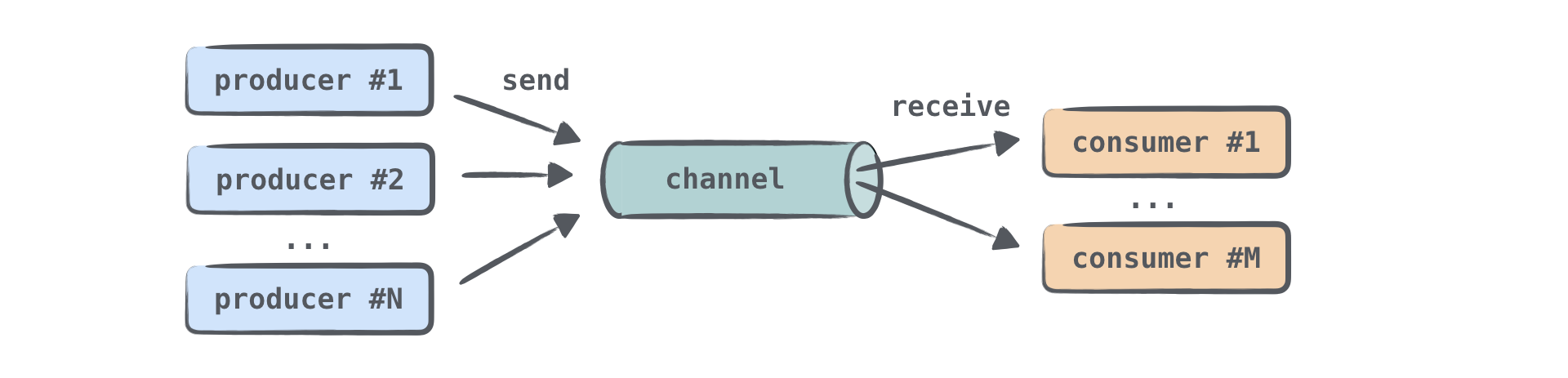
當多個協同程式從同一個管道接收資訊時,每個元素僅由其中一個消費者處理一次。元素一旦被處理,就會立即從管道中移除。
您可以將管道想像成類似於元素的集合,或者更準確地說,是一個佇列,元素從一端加入並從另一端接收。但是,有一個重要的區別:與集合(即使是它們的同步版本)不同,管道可以 暫停 (suspend) send() 和 receive() 操作。這發生在管道為空或已滿時。如果管道大小有上限,管道可能會變滿。
Channel 由三個不同的介面表示:SendChannel、ReceiveChannel 和 Channel,後者擴充了前兩者。您通常建立一個管道並將其作為 SendChannel 執行個體交給生產者,以便只有它們可以向管道發送資訊。您將管道作為 ReceiveChannel 執行個體交給消費者,以便只有它們可以從中接收資訊。send 和 receive 方法都宣告為 suspend:
interface SendChannel<in E> {
suspend fun send(element: E)
fun close(): Boolean
}
interface ReceiveChannel<out E> {
suspend fun receive(): E
}
interface Channel<E> : SendChannel<E>, ReceiveChannel<E>生產者可以關閉管道以指示不再有元素進入。
程式庫中定義了幾種型別的管道。它們在內部可以儲存多少元素以及 send() 呼叫是否可以被暫停方面有所不同。對於所有管道型別,receive() 呼叫的行為都相似:如果管道不為空,它會接收一個元素;否則,它會被暫停。
無限管道 (Unlimited channel)
無限管道與佇列最為相似:生產者可以向此管道發送元素,它將無限增長。send() 呼叫永遠不會被暫停。如果程式耗盡記憶體,您將收到 OutOfMemoryException。無限管道與佇列的區別在於,當消費者嘗試從空管道接收時,它會被暫停,直到發送了新元素。

緩衝管道 (Buffered channel)
緩衝管道的大小受指定數量的限制。生產者可以向此管道發送元素,直到達到大小限制。所有元素都儲存在內部。當管道滿時,下一次 send() 呼叫將被暫停,直到有更多空間可用。

約定管道 (Rendezvous channel)
「約定 (Rendezvous)」管道是沒有緩衝的管道,與大小為零的緩衝管道相同。其中一個函式 (send() 或 receive()) 始終會被暫停,直到另一個函式被呼叫。
如果呼叫了 send() 函式,且沒有暫停的 receive() 呼叫準備好處理該元素,則 send() 會被暫停。同樣,如果呼叫了 receive() 函式且管道為空,或者換句話說,沒有暫停的 send() 呼叫準備好發送該元素,則 receive() 呼叫會被暫停。
「rendezvous」名稱(意為「在約定時間和地點會面」)是指 send() 和 receive() 應該「準時會面」。

合併管道 (Conflated channel)
發送到合併管道的新元素將覆蓋先前發送的元素,因此接收者將始終只獲得最新的元素。send() 呼叫永遠不會被暫停。

建立管道時,指定其型別或緩衝區大小(如果需要緩衝管道):
val rendezvousChannel = Channel<String>()
val bufferedChannel = Channel<String>(10)
val conflatedChannel = Channel<String>(CONFLATED)
val unlimitedChannel = Channel<String>(UNLIMITED)預設情況下,會建立一個「約定」管道。
在接下來的任務中,您將建立一個「約定」管道、兩個生產者協同程式和一個消費者協同程式:
import kotlinx.coroutines.channels.Channel
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
val channel = Channel<String>()
launch {
channel.send("A1")
channel.send("A2")
log("A done")
}
launch {
channel.send("B1")
log("B done")
}
launch {
repeat(3) {
val x = channel.receive()
log(x)
}
}
}
fun log(message: Any?) {
println("[${Thread.currentThread().name}] $message")
}觀看此影片以更深入地了解管道。
任務 7
在 src/tasks/Request7Channels.kt 中,實作 loadContributorsChannels() 函式,該函式同時並行請求所有 GitHub 貢獻者並顯示中間進度。
使用先前的函式:Request5Concurrent.kt 中的 loadContributorsConcurrent() 以及 Request6Progress.kt 中的 loadContributorsProgress()。
任務 7 的提示
為不同存儲庫並行接收貢獻者列表的不同協同程式可以將所有收到的結果發送到同一個管道中:
val channel = Channel<List<User>>()
for (repo in repos) {
launch {
val users = TODO()
// ...
channel.send(users)
}
}然後可以逐一從此管道接收元素並進行處理:
repeat(repos.size) {
val users = channel.receive()
// ...
}由於 receive() 呼叫是循序的,因此不需要額外的同步。
任務 7 的解答
與 loadContributorsProgress() 函式一樣,您可以建立一個 allUsers 變數來儲存「所有貢獻者」列表的中間狀態。從管道收到的每個新列表都會加入到所有使用者的列表中。您聚合結果並使用 updateResults 回呼更新狀態:
suspend fun loadContributorsChannels(
service: GitHubService,
req: RequestData,
updateResults: suspend (List<User>, completed: Boolean) -> Unit
) = coroutineScope {
val repos = service
.getOrgRepos(req.org)
.also { logRepos(req, it) }
.bodyList()
val channel = Channel<List<User>>()
for (repo in repos) {
launch {
val users = service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
channel.send(users)
}
}
var allUsers = emptyList<User>()
repeat(repos.size) {
val users = channel.receive()
allUsers = (allUsers + users).aggregate()
updateResults(allUsers, it == repos.lastIndex)
}
}- 不同存儲庫的結果一旦就緒就會加入管道。首先,當所有請求都已發送且尚未收到資料時,
receive()呼叫會被暫停。在這種情況下,整個 "load contributors" 協同程式會被暫停。 - 接著,當使用者列表被發送到管道時,"load contributors" 協同程式恢復,
receive()呼叫回傳此列表,結果立即更新。
您現在可以執行程式並選擇 CHANNELS 選項來載入貢獻者並查看結果。
雖然協同程式和管道都不能完全消除並行帶來的複雜性,但當您需要理解發生了什麼事時,它們會讓您的生活更輕鬆。
測試協同程式
現在讓我們測試所有解決方案,以確認使用並行協同程式的解決方案比使用 suspend 函式的解決方案更快,並檢查使用管道的解決方案是否比簡單的「進度」版本更快。
在接下來的任務中,您將比較解決方案的總執行時間。您將模擬一個 GitHub 服務,並讓此服務在給定的逾時後回傳結果:
repos 請求 - 在 1000 ms 延遲內回傳答案
repo-1 - 1000 ms 延遲
repo-2 - 1200 ms 延遲
repo-3 - 800 ms 延遲使用 suspend 函式的循序解決方案大約需要 4000 ms (4000 = 1000 + (1000 + 1200 + 800))。並行解決方案大約需要 2200 ms (2200 = 1000 + max(1000, 1200, 800))。
對於顯示進度的解決方案,您還可以檢查帶有時間戳記的中間結果。
對應的測試資料定義在 test/contributors/testData.kt 中,檔案 Request4SuspendKtTest、Request7ChannelsKtTest 等包含使用模擬服務呼叫的簡單測試。
然而,這裡有兩個問題:
- 這些測試執行時間太長。每個測試大約需要 2 到 4 秒,且您每次都需要等待結果。這不是很有效率。
- 您不能依賴解決方案執行的精確時間,因為準備和執行程式碼仍需要額外的時間。您可以加入一個常數,但隨後各機器的時間會有所不同。模擬服務的延遲應該高於此常數,以便您能看到差異。如果常數是 0.5 秒,那麼讓延遲為 0.1 秒就不夠了。
更好的方法是使用特殊的框架在多次執行相同程式碼的同時測試時間(這會進一步增加總時間),但這學起來很複雜且設定繁瑣。
為了解決這些問題並確保具有提供測試延遲的解決方案如預期運作(一個比另一個快),請使用帶有特殊測試排程器的「虛擬 (virtual)」時間。此排程器會追蹤從開始經過的虛擬時間,並即時在實際時間中立即執行所有內容。當您在此排程器上執行協同程式時,delay 將立即回傳並推進虛擬時間。
使用此機制的測試執行速度很快,但您仍然可以檢查虛擬時間在不同時刻發生的事情。總執行時間大幅減少:

要使用虛擬時間,請將 runBlocking 調用替換為 runTest。runTest 接受對 TestScope 的延伸 Lambda 作為引數。當您在此特殊作用域內的 suspend 函式中呼叫 delay 時,delay 將增加虛擬時間,而不是在實際時間中延遲:
@Test
fun testDelayInSuspend() = runTest {
val realStartTime = System.currentTimeMillis()
val virtualStartTime = currentTime
foo()
println("${System.currentTimeMillis() - realStartTime} ms") // ~ 6 ms
println("${currentTime - virtualStartTime} ms") // 1000 ms
}
suspend fun foo() {
delay(1000) // 立即推進而不延遲
println("foo") // 呼叫 foo() 時立即執行
}您可以使用 TestScope 的 currentTime 屬性來檢查目前的虛擬時間。
此範例中的實際執行時間為幾毫秒,而虛擬時間等於 delay 引數,即 1000 毫秒。
要在子協同程式中獲得「虛擬」delay 的完整效果,請使用 TestDispatcher 啟動所有子協同程式。否則,它將不起作用。此排程器會自動從另一個 TestScope 繼承,除非您提供不同的排程器:
@Test
fun testDelayInLaunch() = runTest {
val realStartTime = System.currentTimeMillis()
val virtualStartTime = currentTime
bar()
println("${System.currentTimeMillis() - realStartTime} ms") // ~ 11 ms
println("${currentTime - virtualStartTime} ms") // 1000 ms
}
suspend fun bar() = coroutineScope {
launch {
delay(1000) // 立即推進而不延遲
println("bar") // 呼叫 bar() 時立即執行
}
}如果在上面的範例中使用 Dispatchers.Default 上下文呼叫 launch,測試將失敗。您將收到一個例外,指出作業尚未完成。
僅當 loadContributorsConcurrent() 函式在啟動子協同程式時使用繼承的上下文,而不使用 Dispatchers.Default 排程器對其進行修改時,您才能以這種方式測試它。
您可以在「呼叫」函式時指定排程器等上下文元素,而不是在「定義」它時指定,這提供了更大的靈活性且更容易測試。
支援虛擬時間的測試 API 是 實驗性 (Experimental) 功能,將來可能會發生變化。
預設情況下,如果您使用實驗性測試 API,編譯器會顯示警告。要抑制這些警告,請使用 @OptIn(ExperimentalCoroutinesApi::class) 為測試函式或包含測試的整個類別加入註解。加入編譯器引數,指示編譯器您正在使用實驗性 API:
compileTestKotlin {
kotlinOptions {
freeCompilerArgs += "-Xuse-experimental=kotlin.Experimental"
}
}在本教學對應的專案中,編譯器引數已經加入 Gradle 指令碼中。
任務 8
重構 tests/tasks/ 中的下列測試,改用虛擬時間而非實際時間:
Request4SuspendKtTest.ktRequest5ConcurrentKtTest.ktRequest6ProgressKtTest.ktRequest7ChannelsKtTest.kt
比較套用重構前後的總執行時間。
任務 8 的提示
將
runBlocking調用替換為runTest,並將System.currentTimeMillis()替換為currentTime:kotlin@Test fun test() = runTest { val startTime = currentTime // 操作 val totalTime = currentTime - startTime // 測試結果 }取消檢查精確虛擬時間的斷言註解。
不要忘記加入
@UseExperimental(ExperimentalCoroutinesApi::class)。
任務 8 的解答
以下是並行和管道情況的解決方案:
fun testConcurrent() = runTest {
val startTime = currentTime
val result = loadContributorsConcurrent(MockGithubService, testRequestData)
Assert.assertEquals("Wrong result for 'loadContributorsConcurrent'", expectedConcurrentResults.users, result)
val totalTime = currentTime - startTime
Assert.assertEquals(
"呼叫是並行執行的,因此總虛擬時間應為 2200 ms: " +
"1000 用於 repos 請求,加上 max(1000, 1200, 800) = 1200 用於並行貢獻者請求)",
expectedConcurrentResults.timeFromStart, totalTime
)
}首先,檢查結果是否在預期的虛擬時間準時可用,然後檢查結果本身:
fun testChannels() = runTest {
val startTime = currentTime
var index = 0
loadContributorsChannels(MockGithubService, testRequestData) { users, _ ->
val expected = concurrentProgressResults[index++]
val time = currentTime - startTime
Assert.assertEquals(
"Expected intermediate results after ${expected.timeFromStart} ms:",
expected.timeFromStart, time
)
Assert.assertEquals("Wrong intermediate results after $time:", expected.users, users)
}
}使用管道的最後一個版本的第一個中間結果比進度版本更早可用,您可以在使用虛擬時間的測試中看到差異。
其餘 "suspend" 和 "progress" 任務的測試非常相似 —— 您可以在專案的
solutions分支中找到它們。
接下來的步驟
- 查看 KotlinConf 的 Asynchronous Programming with Kotlin 工作坊。
- 進一步了解如何使用 虛擬時間和實驗性測試套件。